AI/LLM Agents Are Delivering Utter Crap Code - But We Still Need LLMs

Written by Michael Mikhjian
Let me introduce myself: I’ve been writing code since the age of 10, fully self-taught through programming manuals and tutorials.
I skipped my 5th-grade recesses to stay in the library, causing hell on the school’s Windows 2000/ME computers. In high school, I was building proxies to bypass the school’s network, and I spent my short-lived university years building my first SaaS platform, e-commerce projects, and an early client base (and yes, I skipped most of my classes and college parties to focus on code).
At 18, I was among the early developers building full-fledged, database-driven Flash platforms, landing McDonald’s as my first major client and leading the design and development of their Detroit edition platform single-handedly.
Over the next eighteen years, I’ve delivered thousands of web and server projects for over 400 clients, supported multiple government agencies, and contributed early to core technologies powering the modern web—including PHP, MongoDB, NGINX, WebKit, and Varnish.
Now on to business.
I keep a ChatGPT tab open at all times on one of my monitors (always using the latest version), and I regularly use VS Code’s “Ask Copilot” (⌘ + I) throughout the day (GPT 5.2 / Codex MAX / Grok Fast / Gemini / Claude...). I’ve already mastered common patterns such as login flows, password recovery, and other boilerplate features, so the majority of my time is spent writing new code and new designs—developing original algorithms for new products.
ChatGPT helps me explore multiple approaches to a problem—not by “solving” it for me, but again by offering guidance and alternative paths.
The idea that ChatGPT will replace software developers—or be used to write the majority of production code—is far off. At most, certain junior-level tasks may be automated, but senior engineers will thrive; when used correctly, LLMs make them significantly more effective and efficient.
Majority of the web is written with crap code.
In my mid-20s, I realized that the majority of developers were writing crappy, bloated code—100 lines of code to do something that could be written in 10. These developers were literally copying and pasting code from Stack Overflow just to make things “work.” Crappy algorithms, zero understanding of time complexity, and massively bloated WordPress plugins were everywhere, forcing customers to constantly bump up their hosting or servers—burning $100–$500/month just to support shitty code that pegged CPUs at 100%.
In reality, they should’ve been paying $15/month for an AWS (Amazon Web Services) tX.small instance that could easily handle 1,000+ concurrent connections.
That’s when I became the go-to anonymous contact for support. Eventually, I was hired purely for consulting and auditing other developers’ code. I was even contracted by Chrysler to help their massive fleet of developers identify bottlenecks in one of their applications.
Somewhere along the way, I got into white-hat security auditing. I was the guy who found the exploit in Xfinity security cameras that went viral—next thing I knew, their Director of Tech/Security was reaching out trying to figure out how I found it. Then I was contracted by one of the major mobile banking companies to audit their code… 24 hours later, I had over 10,000 customer bank account numbers and SSNs staring me in the face. I digress.
Moral of the story: crap code is everywhere. And LLMs? They just made it worse.
I’m always open to new innovation. That’s how I got started—I was 18 using Flash (RIP). I was also one of the earliest adopters of MongoDB (I was one of their early case studies). I built, in its entirety, a replica of Twitch.tv for the financial markets.
So when LLM agents came out, I tried it… and I tried it… and I tried it. With each new GPT model and version release, it got better—impressively so.
When I asked it to handle simple tasks (junior-developer-level work), it generally pulled them off, assuming the project structures were consistent. But it would add extra CSS, JavaScript, sometimes even start pulling in jQuery code… okay, now I’m having flashbacks again!
GPT 5.2 / Codex-MAX is here. Let's dive in, with a fun game.
I wanted to really test how these latest models worked, so I gave it a pretty gnarly challenge: build a 2D top-down helicopter shooter that’s playable on both desktop and mobile, supports multiplayer, and can run without a server (so it had to be P2P). The results were: very impressive, but also beyond shit.. both equally at the same time.
The output was a browser game that felt like 10 junior developers built it over a week. It was like everything was in the right place, but the actual game logic was a disaster. Simple counters and basic tasks (referencing way above—your boilerplate code) were handled fine, but anything complex—bullet collisions, mobile controls, etc.—was completely off.
So I gave it another shot. I played the role of a “modern developer” (which, honestly, is most of what you see today) and guided the agent to update the logic. For example, for mobile I wrote: Use the left thumb (first tap) to control the movement of the helicopter, and the right thumb (second tap) to control aiming and shooting. Sure enough, it updated and technically pulled it off—but it was buggy as hell.
Maybe a dozen prompt iterations later, it got the controls as close as possible, but what I noticed was that it just kept rewriting the code… over and over… until it eventually got closer. Even then, it still required heavy prompt engineering to get there.
In my initial prompt, I also told it to make the multiplayer networking similar to Call of Duty. From a high-level review, the protocol didn’t look terrible. It set up a host/peer architecture, configured WebRTC packets and snapshots correctly—but was it playable? Not even close. It was beyond laggy, not because of the protocol itself, but because it was sending a full game-state snapshot every 60Hz. The peer browser was completely overwhelmed with data and constantly crashing.
I tried to “prompt engineer” the networking as well (again, the goal was to do this without manually coding), and I easily burned countless hours watching the agent rewrite the same shitty code over and over. It got better, then worse, then better, then unplayable, then great—but missing things—and then absolute shit again.
The agent simply could not pull off P2P efficient logistics correctly. Ultimately to make P2P work I would need to manually rewrite the layer to make it playable.
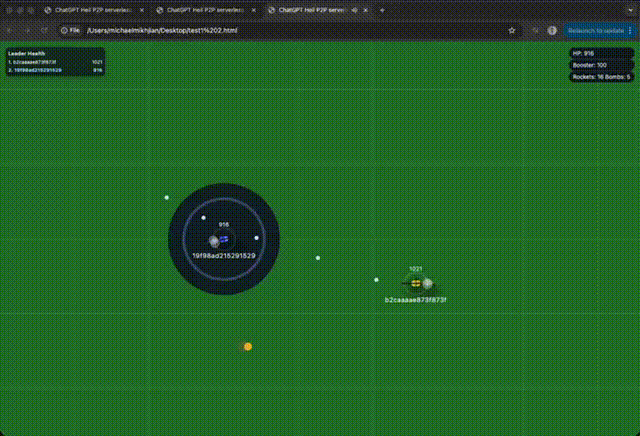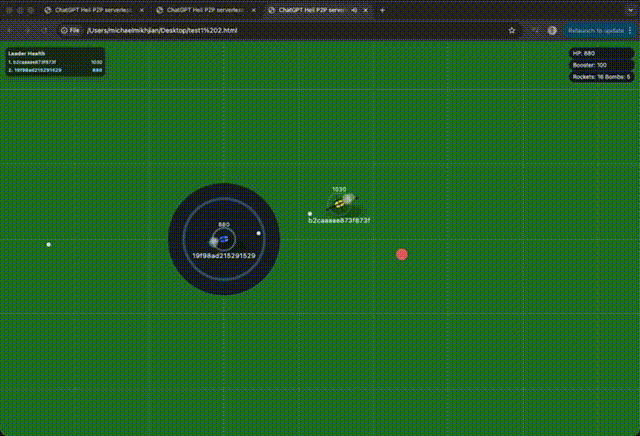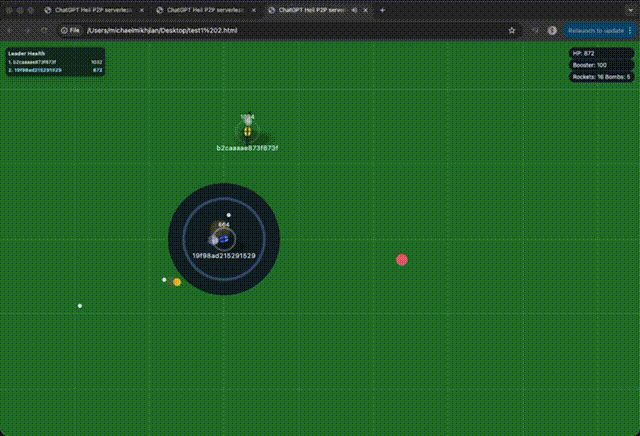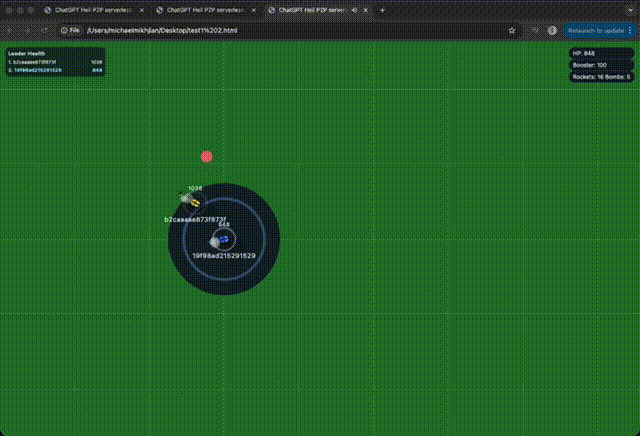
I had an idea: how would an agent handle a massive, drastic change?
I told the agent to rewrite the game’s entire P2P networking layer and replace it with a Node.js server to improve efficiency. After about 10 minutes of rewriting code live in front of me, it impressively pulled it off. I specifically asked it to keep the server layer as vanilla as possible—no plugins or extensions—and it did exactly that.
I booted up the server, and right out of the box, it worked. The WebSocket layer was correctly streaming data. However, the game logic itself clearly lacked domain knowledge—for example, what should happen when a player dies. That wasn’t an expectation, though, since I never prompted it with those rules.
I posted the game on Reddit and quickly garnered over 30k views. It even got deleted from a few subreddits and earned me a ban from one because it pissed off some developers—which, honestly, I don’t blame them for. As expected, I received dozens of brutal reviews of the gameplay, mentioning lag, frame drops, and a complete bug hell.
I then ran maybe 30–40 more iterations using GPT’s Codex Max, and again, I was impressed that it could clean things up and make the game somewhat playable. But after repeatedly prompting it with things like “make the code more efficient,” I started to notice a pattern. It was often just looping the same logic, reshuffling code, or refactoring without producing any real improvement.
After countless more hours, I realized that no amount of prompt engineering was going to push it much further. It felt like working with a junior developer who was constantly searching Stack Overflow, copy-pasting solutions from random sources, and then cleaning them up to match the existing code style—ultimately resulting in the same low-quality game. Not to mention, the server app itself constantly crashing after 10 minutes because of buffer data getting too big!
The future of LLM.
Innovation is not only about logic—where logic means good reasoning versus bad reasoning—but it must eventually become logical to survive.
The idea that software development can rely solely on large language models is misguided. Human judgment and creativity are essential, and more importantly, mastery of the craft itself is required. When deep expertise is combined with LLMs, the result is a powerful synergy that amplifies both creativity and efficiency, rather than replacing the human element.
While LLMs are useful for tasks like code generation, bug fixes, and optimization hints, they don’t replace the kind of reasoning that real problem-solving requires. They lack context, judgment, and an understanding of trade-offs beyond what’s been encoded into them.
What actually elevates their usefulness is human mastery of the craft—knowing the domain, understanding the system as a whole, making informed decisions, and adapting when requirements or constraints change. Used this way, LLMs become leverage rather than a crutch.
The real value emerges when experienced engineers pair their expertise with these tools, creating a feedback loop where creativity explores possibilities and logic validates them. The result isn’t just faster output, but better software—more reliable, more maintainable, and able to scale and evolve over time.
Oh and if you're bored, here's a link to that game that only took hundreds of iterations to get somewhat playable: ChatGPT Heli Multiplayer Game ~ https://dev.mkn.us/rr.php
TL;DR: LLMs are genuinely useful and many experienced developers use them daily, but they’re being oversold. They work best as tools that amplify expert developers, not as replacements for them. They can generate and refactor code well, but they hit a hard ceiling on deep reasoning, architecture, and optimization. In expert hands, they save time; treated as autonomous engineers, they produce confident-looking but low-quality results.